Synthetic population COVID model
The consortium of TU Wien, DWH & CSH developed a synthetic covid model that was used in forecasting the pandemic and deriving suggestions for interventions.
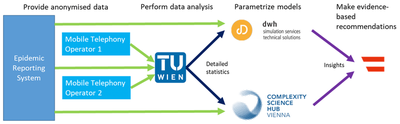
Data provisioning pipeline
The project set up the following pipeline to gather and analyse data relevant to COVID-19. Two mobile telephony operators in Austria provide anonymised mobility data for use in COVID-19 related research. The researchers have specified the aggregated information that is required for the analyses. This aggregated information is calculated on the computational infrastructure of each operator and made available to the researchers. The following data is provided: counts of mobile devices at certain points of interest (e.g. the metro stations of Vienna), radius of gyration data (an average over a geographical region of how far mobile devices move during the day), and origin-destination matrices (counts of how many devices move between areas of Austria). The origin-destination matrices, in particular, allowed the agent-based models to be improved. For one of the studies described below, anonymised call patterns were also made available.
Together with data from the state administration, originally from the Epidemic Reporting System but later extended to further datasets, it was possible to carry out simulations of the spread of disease. Results of the simulations were used as the basis for evidence-based recommendations to the Austrian government through the COVID-19 Forecast Consortium1. The pipeline created in this project illustrates a very fruitful collaboration between government administration, business, and research in obtaining insights the support the response to a crisis – it should serve as a starting point for further collaborations also in non-crisis times.
Below we describe results that were obtained in the project.
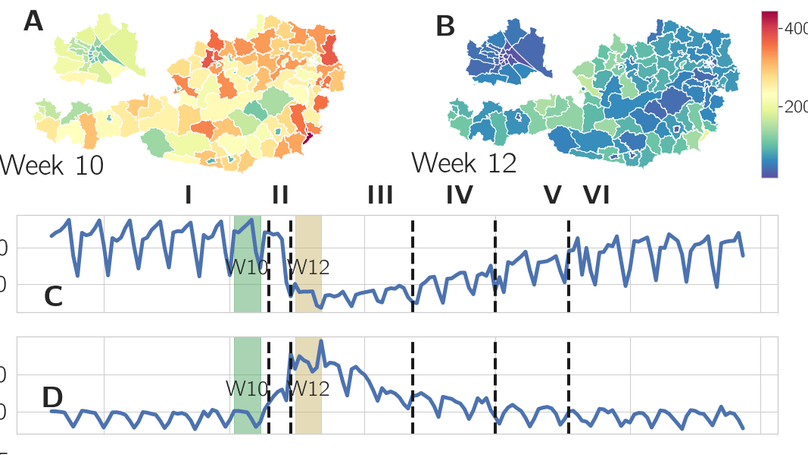
Country-wide Mobility Changes Observed using Mobile Phone Data during the COVID-19 Pandemic
We assessed the effect of the lock-down in March 2020 quantitatively for all regions in Austria and presented an analysis of daily changes of human mobility throughout Austria using near-real-time anonymized mobile phone data.
We developed an efficient data aggregation pipeline and analysed the mobility by quantifying mobile-phone traffic at specific points of interest (POI), analysing individual trajectories and investigating the cluster structure of the origin-destination graph. We found a reduction of commuters at Viennese metro stations of over 80% and the number of devices with a radius of gyration of less than 500 metres almost doubled. The results of studying crowd-movement behaviour highlight considerable changes in the structure of mobility networks, revealed by a higher modularity and an increase from 12 to 20 detected communities. We demonstrate the relevance of mobility data for epidemiological studies by showing a significant correlation of the outflow from the town of Ischgl (an early COVID-19 hotspot) and the reported COVID-19 cases with an 8-day time lag. This research indicates that mobile phone usage data permits the moment-by-moment quantification of mobility behaviour for a whole country. Furthermore, we evaluated the impact of COVID-19 on relative changes in aggregated mobility using mobile-phone data relative changes in aggregated mobility using mobile-phone data. Evaluating relative changes leads to additional insights that would remain hidden when only evaluating absolute changes. By applying compositional data analysis we showed that formerly hidden information becomes available: we see that the elderly population groups increase relative mobility and that the younger groups, especially on weekends, also do not decrease their mobility as much as the others.
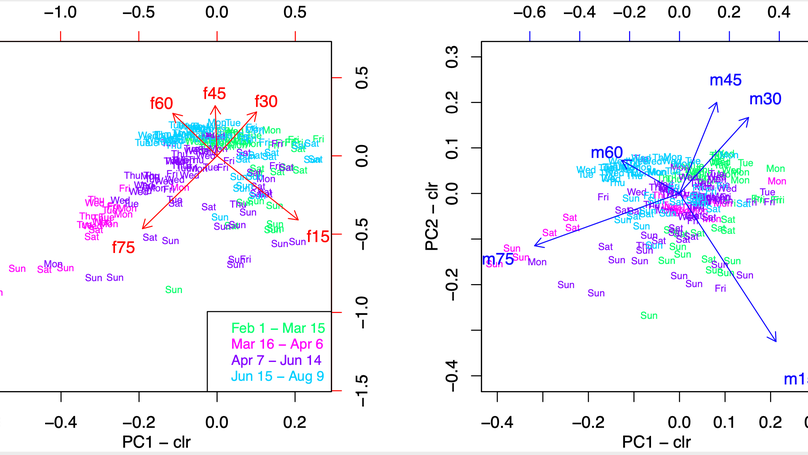
Behavioral Gender Differences are Reinforced during the COVID-19 Crisis
Behavioral gender differences are known to exist for a wide range of human activities including the way people communicate, move, provision themselves, or organize leisure activities. Using mobile phone data from 1.2 million devices in Austria (15% of the population) across the first phase of the COVID-19 crisis, we quantify gender-specific patterns of communication intensity, mobility, and circadian rhythms. We show the resilience of behavioural patterns with respect to the shock imposed by a strict nation-wide lock-down that Austria experienced in the beginning of the crisis with severe implications on public and private life. We find drastic differences in gender-specific responses during the different phases of the pandemic. After the lock-down gender differences in mobility and communication patterns increased massively, while sleeping patterns and circadian rhythms tend to synchronize. In particular, women had fewer but longer phone calls than men during the lock-down. Mobility declined massively for both genders, however, women tend to restrict their movement stronger than men. Women showed a stronger tendency to avoid shopping centres and more men frequented recreational areas. After the lock-down, males returned back to normal quicker than women; young age-cohorts return much quicker.
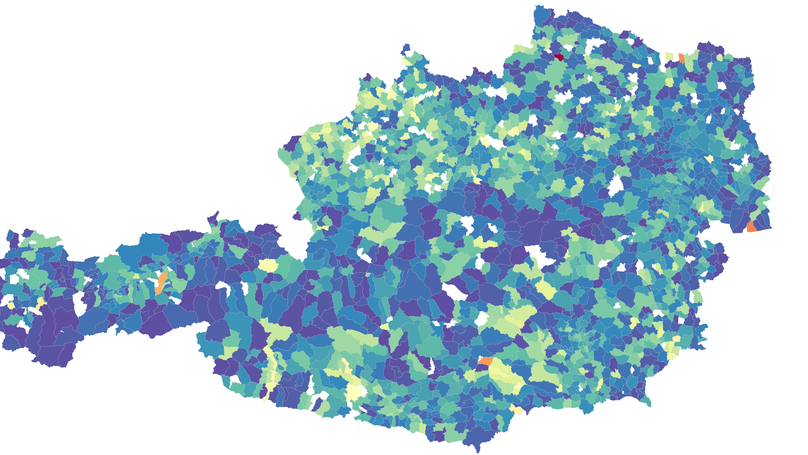
Origin Destination Matrices for Parametrization of Agent-Based Epidemic Models
In microscopic epidemic models – models in which each individual is modelled separately as an agent – contacts and infections are typically modelled by separate processes. Agents first decide whom they contact, and in a second step the model decides on whether the contact led to transmission of the disease. Splitting up these two processes allows a precise image of reality and allows the modelling of various containment policies directly.
The agent-based COVID model developed by TU Wien and dwh GmbH in the course of a project initiative in spring 2020 (Evaluation of Contact-Tracing Policies Against the Spread of SARS- CoV-2 in Austria– An Agent-Based Simulation, Evaluation of undetected cases during the COVID-19 epidemic in Austria) has a deep model logic that samples adequate contact partners via locations like households, schools or workplaces. Still, for leisure time contact partners, the developed algorithms turned out to be inaccurate and insufficient. Here the parameter that should influence whether a contact occurs should be the individual’s location in form of a GPS coordinate.
There are multiple ways in which distance can be used to influence a sampling method. Specifically, increased likelihood for small Euclidean distance is clearly the most intuitive approach. Unfortunately, it is, from the modelling perspective, also the most inaccurate strategy since it fully neglects the topology of the region. Moreover, there is no data available that allows for valid parametrization.
Availability of detailed mobile phone data has allowed new strategies based on political regions. Origin-destination matrices contain information about how many trips individuals living in one region performed into a second region within a certain time frame. By switching to the approach with an OD Matrix on municipality level (about 2100 in Austria), face validity2 of the simulation model could be improved vastly. The contact network was freed from implausible transmission chains over multiple federal states and depicts the heterogeneity of the urban and rural regions much better than a simple distance-based sampling method.
Summarizing, the improved sampling method was key to analysis of regional COVID-19 policies, such as regional screening programs3 and regional lockdowns 45.
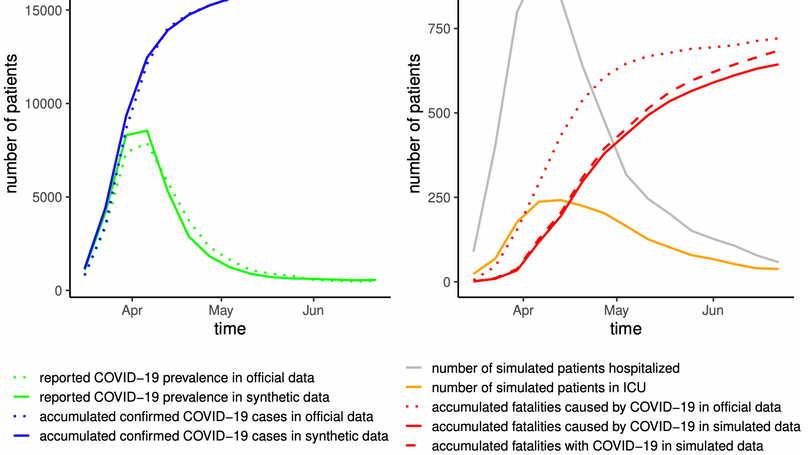
Synthetic Reproduction and Augmentation of COVID-19 Case Reporting Data by Agent-Based Simulation
In particular in Austria, implemented epidemiological (data) procedures and systems suffer from a long period of neglect and were initially not designed for quick response. Inconsistent and fractured (data) management of health care institutions and authorities can hinder the assessment of available and occupied resources. Data may be collected and published independently by regional authorities and health care institutions with different electronic systems, semantics and interpretation. For example, in Austria, public hospitals are operated by nine federal states; until the current epidemic, there was no nationwide reporting on the occupancy of intensive care units (ICU). Furthermore, decision makers and authorities only slowly or insufficiently implement new technical methods for surveillance including detailed case documentation, registration of individual quarantine orders and identifying persons at risk of infection via contact tracing. For example, the time periods between indication of COVID-19, testing and test result, which are crucial for assessing the effectiveness of the testing-tracing-isolating (TTI) strategy, are often not recorded. Especially if reporting systems are implemented in a hurry, data may not be annotated or documented. Access to the data for researchers is often complicated by administrative procedures. Even worse, data may only be available through the media, in non-machine-readable formats data may only be available through the media, in non-machine-readable formats or held back completely due to political reasons or unresolved data privacy issues.
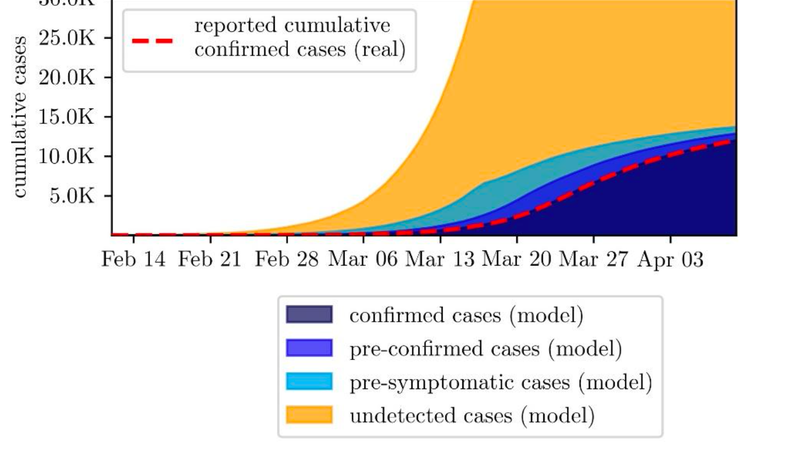
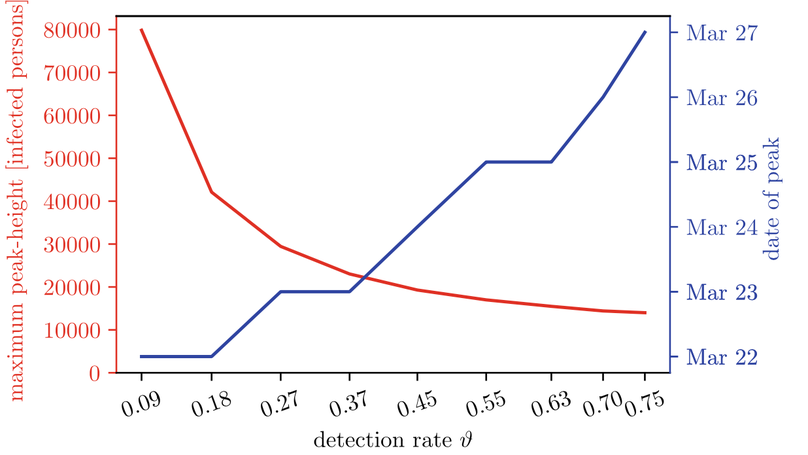
For these reasons, we aimed to synthetically reproduce, pad and augment a data set of reported SARS-CoV-2 cases in Austria by means of our event-driven simulation model. The model is focused on the correct representation of the statistical configuration of the Austrian population, on the mapping of the reported incidence and on the actual history of the implementation and suspension of countermeasures. We furthermore take a patient-centered perspective by aiming for an accurate reproduction of patient pathways taking into account their variability and gradual transformation.
The generated synthetic data is characterized by reduced sparsity, logical consistency (i.e. no data-errors) and information included that is not observable in reality (e.g. the moment of infection. Our synthetic data reflects the original data set on a longitudinal and aggregated scale and displays effects that are known to exist in reality but cannot be recorded on a population scale.
For more information the reader is referred to Synthetic Reproduction and Augmentation of COVID-19 Case Reporting Data by Agent-Based Simulation. The publicly available synthetic dataset is shared.
Face Validation by Visualization of Infection Chains
Considering a simulation model in its most reduced form as a black box with input, model state and output, agent-based models clearly distinguish themselves from more classic approaches like differential equations by an enormously huge state-space compared to the sizes of input and output space. While the actual state of the model consists of all possible states and actions of all individual agents, the outputs are typically dynamically changing aggregates of them. Similarly, inputs are aggregated distributions that the state is sampled from.
As a result, a validation process of an agent-based model cannot be limited to validation of the input and output but needs to go deeper into the model logic. The most common method to do this is the concept of face validity. Hereby a person, not involved in the modelling process and optimally a domain expert, is asked to judge the validity of a model by analysing visualizations of model processes, model states, model structure and qualitative model results. As a key element of this validation process, very specific visualization types need to be designed that support analysis of potentially non-simulation experts.
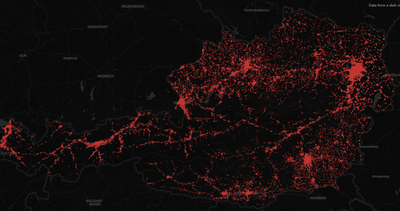
In the process of the validation of our agent-based COVID-19 simulation model, a number of different visualizations were developed to support face validation. First, infection processes were displayed according to the simulated coordinates of the transmission place. Studying the time-dynamics of the infections, regional spread of the infections can be observed.
In a second step, a network visualization was designed to enable a deeper look into the structure of simulated infection clusters. In contrast to the real system, we can differentiate between “infection clusters”, that is all persons being infected by a certain index case, and “detection clusters”, that is all persons in an “infection cluster” that are also found by a positive test. By direct comparison between modelled and actually traced detection clusters (gathered by AGES) we could find strong similarities, but also differences between simulated and real clusters. The increased skewness of the size of the reported clusters was found to be the most significant difference. We found that the way certain settings favour or handicap contact/cluster tracing in the real system would be one explanation for this behaviour. For example, transmissions that happened at a birthday party are easier to find than those happening in the supermarket.
Small samples of the established visualizations are found below and, interactively, on https://m1.dwh.at/covid/tracing.html.
https://www.sozialministerium.at/Informationen-zum-Coronavirus/Neuartiges-Coronavirus-(2019-nCov)/COVID-Prognose-Konsortium.html ↩︎
To measure face validity, a person, not involved in the modelling process and optimally a domain expert, is asked to judge the validity of a model by analysing visualizations of model processes, model states, model structure and qualitative model results. ↩︎
https://www.dwh.at/news/covid-19-modellbasierte-evaluierung-von-screening-strategien ↩︎
https://www.heute.at/s/experte-plaediert-fuer-regionale-massnahmen-100130353 ↩︎
https://kurier.at/wissen/corona-situation-in-oesterreich-popper-fuer-regionale-massnahmen/401203243 ↩︎
Publications
Funding
This project has been funded by the Vienna Science and Technology Fund (WWTF) through project COV20-035.
![]()
Cooperation partners
We thank the cooperation partners for their continued support:
Magenta
T-Labs

DREI